端智能是指在终端设备上运行的智能应用程序,这些应用程序利用终端设备的计算能力、存储能力等资源,而不依赖外部的服务端来实现一些智能化的功能。
目前我所了解到的,主要以前端技术栈为主,比如 TensorFlow.js、onnxruntime-web 等。这两个都能够实现在 Web 端或本地 Node 服务上进行机器学习模型的训练和部署。
当然端智能只是一个概念,其它技术栈的 GUI 程序也可以实现端智能的功能,比如 Python 的 PyQt、C++ 的 Qt 等。这块由于专业知识有限,我还没有涉及过。
先说端智能的挑战
我认为目前端智能的挑战包括但不限于以下几点:
- 不好存储较大的模型(加载时间长,占用内存大 😅)
- 端智能设备的计算能力有限, 运行复杂的模型不友好,不适用于 ToC ,因为用户的机器参差不齐,不好保证较好的用户体验, (不过这块主要是非常的节约成本,因为不需要再去购买昂贵的服务器 👍)
实现
这里我主要通过 TensorFlow.js、onnxruntime-web 的两个方向来讲一下。
实现 1:TensorFlow.js
TensorFlow.js 是一个用于使用 JavaScript 进行机器学习开发的库。
它可以使用现成的 JavaScript 模型,也可以转换我们 AI 团队的 Python TensorFlow 模型用来在浏览器中或 Node.js 下运行。
由于我主攻前端方向,缺乏机器学习的相关经验,我在这块的造诣只停留在使用 KNN 分类做识别手写数字或者调用二次封装的模型类库实现诸如上面偏应用层的程度。

觉得这块比较好玩,主要是用 TensorFlow.js 官方已经训练好的模型,或者二次封装的类库来做一些图像处理的功能,比如实时处理摄像头的画面,图片,视频,gif 等
比如我前年做的一个 demo-姿态识别

这个姿态识别的 demo 就是是基于 TensorFlow.js 实现的,里面用的是 PoseNet, 当然这方面的模型有很多,你完全可以选择适用于自己场景的,MoveNet, PoseNet, BlazePose...
这个具体实现可以看这篇文章:WebRTC + Tensorflow.js 在运动健康类项目中的前端应用
或者眼动识别示例:
仓库地址: https://github.com/wangrongding/frontend-park
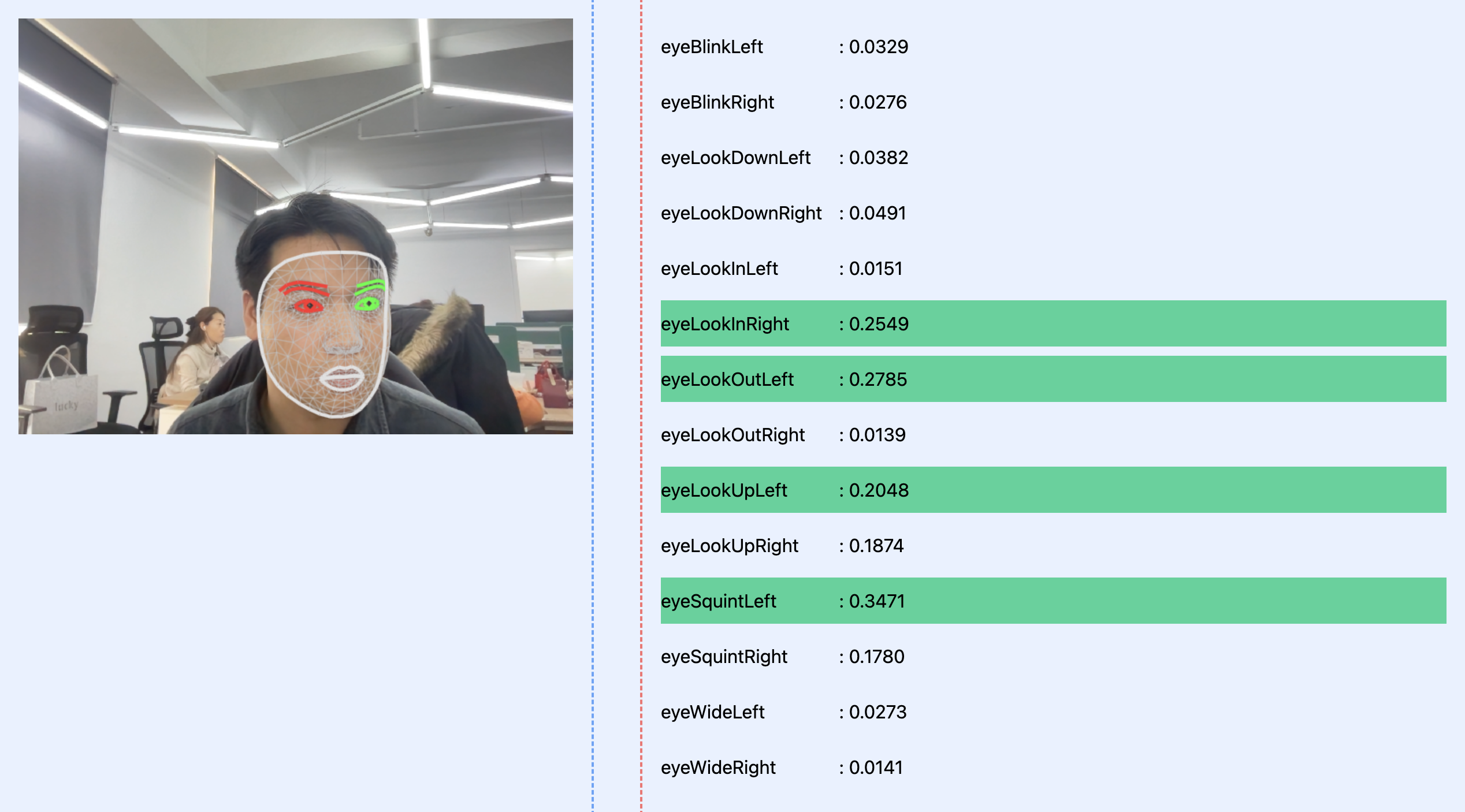
感兴趣的同学也可以去下载一个 MNIST 数据集,对于想要学习和测试相关算法,这是一个很好的数据库。
MNIST 数据集:http://yann.lecun.com/exdb/mnist/ (地址要复制链接到浏览器打开,直接点击此处进入需要账号和密码)
实现 2:onnxruntime-web
onnxruntime-web 是一个用于在浏览器中运行 ONNX 模型的库。
onnx 是一个用于表示机器学习模型的开放标准,可以用于在不同的机器学习框架之间共享机器学习模型。
比如我最近参与的一个项目,就是在浏览器中通过 onnxruntime-web 来加载 onnx 模型,配合 opencv-ts 来实现涂抹消除的功能
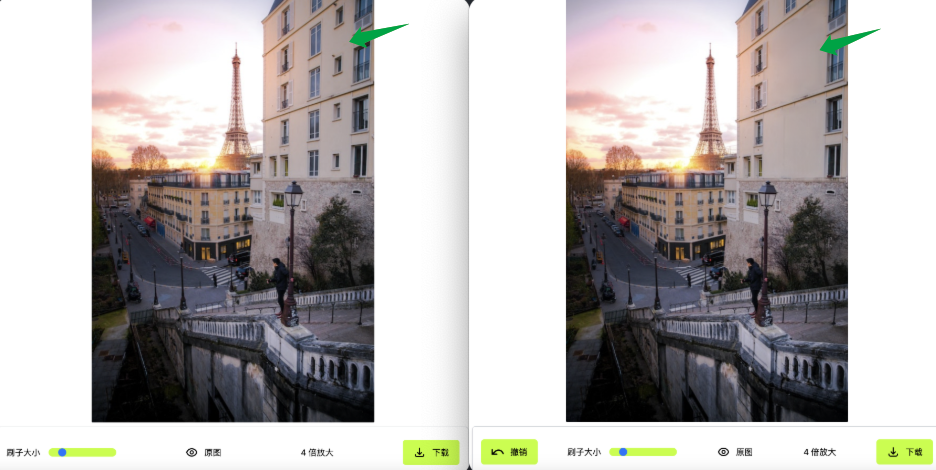
体验地址:inpaint-web
仓库地址:github: inpaint-web

这里面的 onnx 模型是通过 PyTorch 写完转成 onnx 格式的模型,这里具体实现可以完全交给我们负责 AI 方向的同学
拿到 onnx 模型后,通过 onnxruntime-web 就可以加载到浏览器中
剩下的,就是业务代码:这里面是使用 opencv-ts 来处理图像,模型接收一个输入,然后会输出一个结果,通过处理这个数组我们就能拿到 ImageData,然后巴拉巴拉你可以拿这个 ImageData 做你想做的事情就行。
哪个更好?
个人认为采用 onnxruntime-web 来加载模型的方式更好,也更符合区分职能的团队协作方式。只需要协商好模型的输入输出,然后就可以分工合作了。
在工程部署中,基本不会采用 ONNX 自带的 API 去搭建网络,通常都是采用其他深度网络学习框架训练模型,然后将训练好的模型直接导出成 ONNX 模型现在很多深度学习框架都支持了 ONNX,方便了模型的部署和在各个框架之间转移,未来可期 😃
这样也更方便专门负责做这块的同学可以用自己的技术栈来实现(TensorFlow, Keras, PyTorch...), 我认为这本身为 AI 框架的采用提供了更大的灵活性。
然后 onnxruntime-web 可以选择在 CPU 和 GPU 上运行。
在 CPU 上运行的时候,采用 WebAssembly 以接近原生速度执行模型。
在 GPU 上运行的时候,由于 WebGPU 目前还是实验性的,所以目前还是用 WebGL 来运行的。
模型的获取
这些地方都有很多的模型可以直接拿来用,如果自己有相关经验,也可以自己训练模型。
- TensorFlow Hub (https://tfhub.dev), 今天看到已经改名了,会重定向到(https://www.kaggle.com/models)
- TensorFlow.js (https://www.tensorflow.org/js/models)
- PyTorch Hub (https://pytorch.org/hub)
- huggingface (https://huggingface.co/models)
- ONNX models (https://onnx.ai/models)
端智能的应用场景
最早有这个概念的认识,是 20 年刚毕业的时候,我的第一家公司(医疗行业),当时就在探索端智能的应用场景,那时候感觉前端在 AI 方向的生态都还很不完善,也可能是我不知道,但是现在看来,这块的生态已经很完善了,而且发展的特别快,特别是这两年。
背景是,专家或者医生一天要看很多片子,看到后面很容易把明明有问题的给忽略了,所以我们想通过一些算法来帮助医生更快更准确的找到问题所在。
当时我们的产品主要是互联网医院的生态软件,核心业务就是将 CT、MR 等影像进行 3 维重建,方便专家看片子,比 2D 的片子更容易发现问题所在。
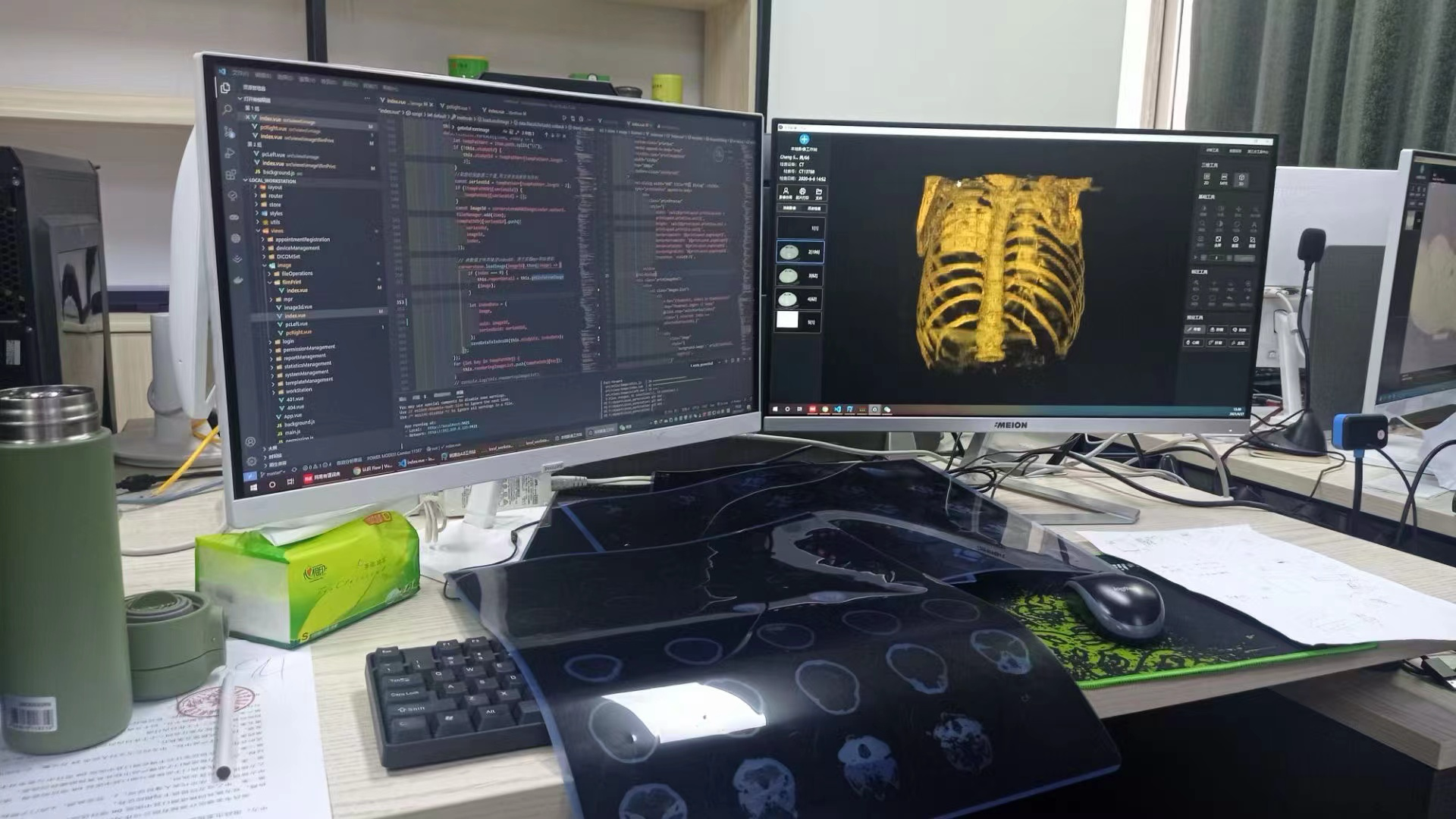
这个过程中,我们就需要用到一些图像处理的技术,比如图像去噪、增强等然后输入给模型等待结果,种种原因,最后我们实现的是一个假的端智能,本地起个服务,前端调本地的接口 😅😅
结论
- 端智能未来肯定有前景(前提是网络越来越好,例如 5G 普及「按需加载影响体验?」,硬件越来越强算力越来越猛, 例如人手一块 4090🫢)
- 小型模型友好,中型吃力,大型顶不住
- 简单任务能给公司节约成本